babylon
Use concurrent counter optimize bvar
原理
brpc的bvar在实现高并发计数器时,核心机制是采用『可遍历的线程局部变量』去除了多线程计数间的竞争。但是计数线程和收集线程之间依然存在竞争场景,尽管收集任务运行频率非常低,但为了完备性和正确性,这个竞争依然需要被合理解决。bvar在这个问题上使用了两种解法
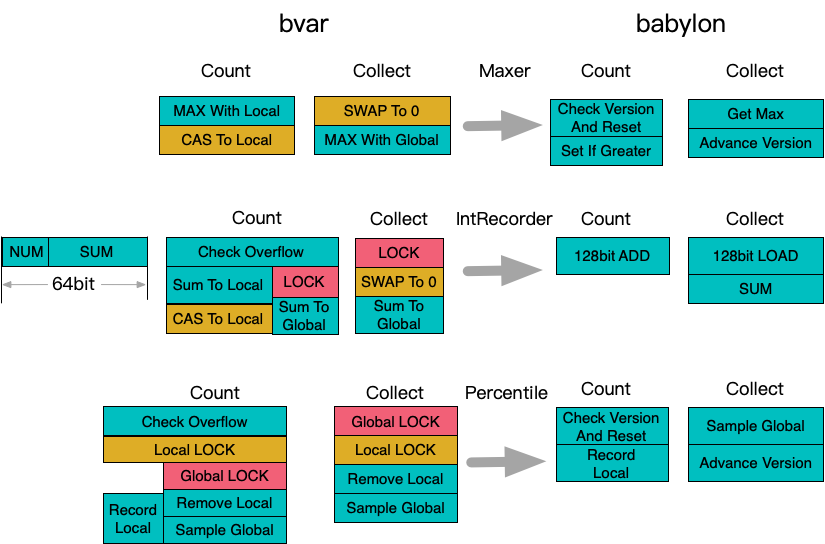
- 对于可以原子更新的基础类型,比如bvar::Adder/bvar::Maxer/bvar::IntRecorder等,采用原子CAS解决竞争
- 对于不可原子更新的复杂类型,比如bvar::detail::Percentile,采用每个线程独立锁保护解决竞争
- 对于bvar::IntRecorder/bvar::detail::Percentile,由于存在计数溢出场景,会在溢出时采用锁保护方式提前提交到全局结果
但是对于上面几个计数器场景,理论上可以进一步进行针对性优化
- Adder:
int64_t更新本身保证原子性,直接+=实现替换CAS - Maxer: 通过全局维护版本号,每次收集重置时递增版本,计数线程在校验版本号发现变更时自助清零,可以避免使用CAS
- IntRecorder: 利用现代CPU对128bit写入操作原子生效的隐式特性扩展值域避免溢出
- Percentile:
- 通过类似Maxer的全局版本概念去除收集线程操作线程局部变量的场景
- 每个线程局部采样桶和收集线程通过采样size上的acquire-release同步替换锁保护
- 每个线程通过局部蓄水池采样处理溢出,避免提前提交操作中的全局锁
示例构成
:recorder: bvar::Adder/bvar::Maxer/bvar::IntRecorder/bvar::detail::Percentile替换实现:example: 性能演示程序
性能演示
计数性能
| AMD EPYC 7W83 64-Core Processor | bvar | babylon |
|---|---|---|
| adder | 12.51 ns | 7.68 ns |
| maxer | 12.53 ns | 8.21 ns |
| int_recorder | 15.48 ns | 9.82 ns |
| latency_recorder | 132.36 ns | 28.66 ns |